High performance computing
There are at least 5 different layouts for integrating in parallel large stacks of images which can be ordered from the simplest to the most technical:
0. Naive serial loop with parallel decompression (thanks to OpenMP in bitshuffle-LZ4) and parallel integration (thanks to OpenMP, CSR matrix multiplication). This approach was developed at a time computers had few cores (~4) but the way OpenMP is used here does not scale at all and it is often slower than the serial version on “many-core” systems (modern servers featuring more than 32 cores). This is the base performance level against which other methods will be compared. It is demonstrated in any of those tutorials.
1. Multithreading: While threads are known to be inefficient in Python due to the GIL, this pattern can be effective when all code is GIL-free. One could design a pipeline with one reader using direct-chunk-read and a pool of threads performing decompression + integration. Decompression must be tuned to use a single thread to avoid cache poisoning. This method is demonstrated in the first tutorial, it first shows linear speed-up then stagnates: 30x speed up is measured on 2x32core.
2. Multiprocessing: This is known to be efficient under Linux thanks to the fork mechanism but one has to use spawn, like under Windows to be compatible with GPU processing. One GPU can host up to 15 parallel instances. This method does not yet have a tutorial to dmonstrate it.
3. Full GPU processing: this requires the hardware (starts ~10k€) and some software blocks like the LZ4 decompression, the bitshuffling and the azimuthal integration to be all performed on the GPU. The advantage is that one benefits from the direct-chunk-read from HDF5, transfers little data to the GPU. Probably one of the best solution with its simple design (but complicated GPU code under the hood) which became much simpler recently with silx v1.2 (development for now). This is demonstrate in the second tutorial.
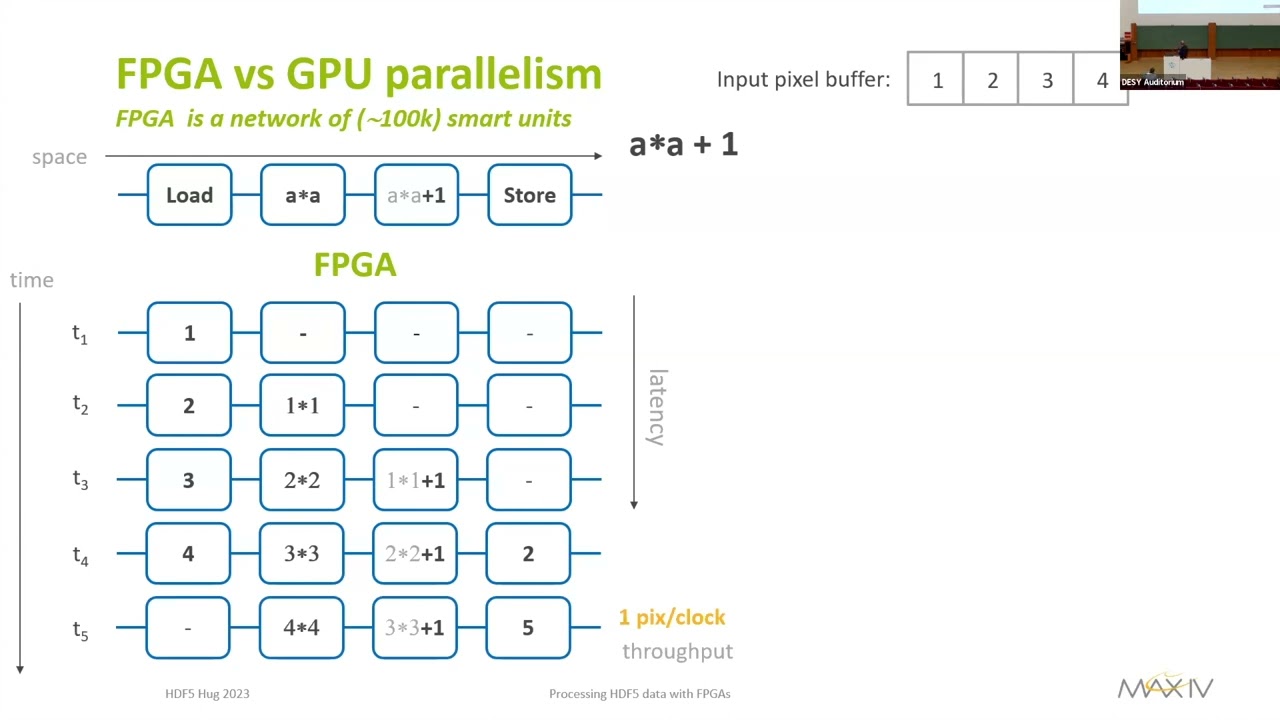
4. Full FPGA processing: It is proven to be up to 10x faster compared to GPU but requires even more specialized hardware and staff: both decompression and integration can be performed there.
Here are a couple of videos on this topic:

and about FPGA:
The notebook hereafter present some of those approaches (0, 1 and 3):