Multiprocessing on GPU
In this tutorial, the idea is to parallelized the reading of several HDF5 files in different processes and to perform the azimuthal integration on the GPU together with the Bitshuffle-LZ decompression.
The size of the problem is 1000 files containing 1000 frames each of 4Mpix. That’s one million frames. Reduced data are 1000x1000x1000 in single precision float.
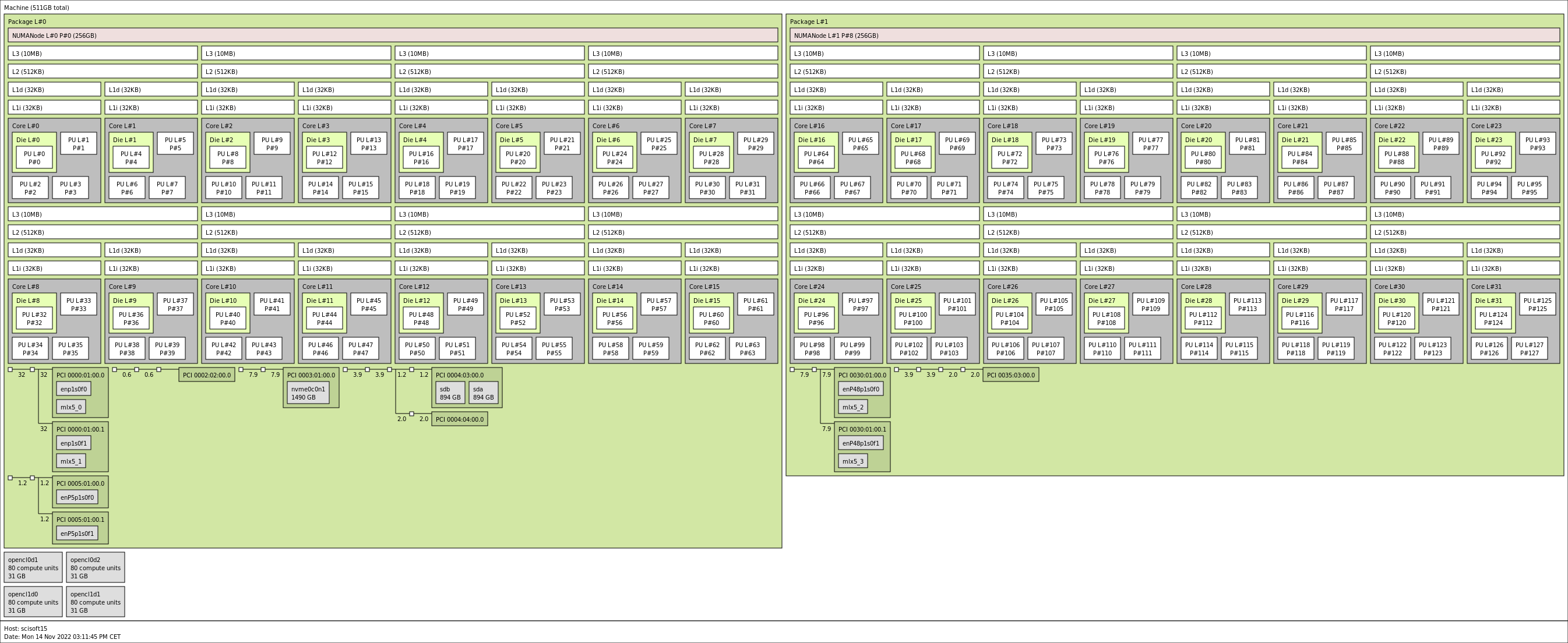
This is an extreme case where we will try how to use all resources of the computer, so the first thing to do is to determine the topology of the computer: * AC922 computer from IBM with power9 processors. * 2 processors, 2x16 cores. Two cores share the L3-cache * 2 GPUs which can be accessed either via POCL or via the nvidia driver (the later is broken).
Disclaimer: * We use multiprocess instead of the multiprocessing library to be able to demonstrate the precedure with the jupuyter notebook. * We use SharedArray to provide a natural way of sharing the result array in memory between processes.
[1]:
%matplotlib inline
# use `widget` for better user experience; `inline` is for documentation generation
#Topology of the computer:
!lstopo /tmp/topo.png
from IPython.display import Image
Image(filename='/tmp/topo.png')
Failed to open /tmp/topo.png for writing (File exists)
[1]:
[2]:
import os
import glob
import concurrent
import time
import json
from matplotlib.pyplot import subplots
import multiprocess
from multiprocess import Process, Value, Array
if "mpctx" in globals():
mpctx = multiprocess.get_context('spawn')
else:
multiprocess.set_start_method('spawn')
mpctx = multiprocess.get_context('spawn')
import numpy
import hdf5plugin
import h5py
import pyFAI
print("pyFAI version: ", pyFAI.version)
import SharedArray
from silx.opencl import ocl
from silx.opencl.codec.bitshuffle_lz4 import BitshuffleLz4
import inspect
import collections
Item = collections.namedtuple("Item", "index filename")
MAIN_PROCESS = multiprocess.parent_process() is None
print(ocl)
pyFAI version: 0.22.0-dev10
OpenCL devices:
[0] Portable Computing Language: (0,0) pthread-POWER9, altivec supported, (0,1) Tesla V100-SXM2-32GB, (0,2) Tesla V100-SXM2-32GB
[1] NVIDIA CUDA: (1,0) Tesla V100-SXM2-32GB, (1,1) Tesla V100-SXM2-32GB
[3]:
#This cell contains the parameters for all the processing
params = {
"DEVICES": [[0,1],[0,2]],
"NWORKERS": 4,
"FRAME_PER_FILE": 1000,
"NFILES" : 1000,
"NBINS" : 1000,
"DETECTOR":"Eiger_4M",
"pathname" : "/tmp/big_%04d.h5",
"pathmask" : "/tmp/big_????.h5",
"dtype" : "float32",
"SHARED_NAME" : "shm://multigpu",
"array_shape" : [1000, 1000, 1000],
}
with open("param.json", "w") as w: w.write(json.dumps(params, indent=2))
for k,v in params.items():
globals()[k] = v
[4]:
def build_integrator(detector=DETECTOR):
"Build an azimuthal integrator with a dummy geometry"
geo = {"detector": detector,
"wavelength": 1e-10,
"rot3":0} #work around a bug https://github.com/silx-kit/pyFAI/pull/1749
ai = pyFAI.load(geo)
return ai
[5]:
# Generate a set of files
def generate_one_frame(ai, unit="q_nm^-1", dtype="uint32"):
"""Prepare a frame with little count so that it compresses well"""
qmax = ai.array_from_unit(unit=unit).max()
q = numpy.linspace(0, qmax, 100)
img = ai.calcfrom1d(q, 100/(1+q*q))
frame = numpy.random.poisson(img).astype(dtype)
return frame
def generate_files(img):
cmp = hdf5plugin.Bitshuffle()
filename = pathname%0
shape = img.shape
with h5py.File(filename, "w") as h:
ds = h.create_dataset("data", shape=(FRAME_PER_FILE,)+shape, chunks=(1,)+shape, dtype=img.dtype, **cmp)
for i in range(FRAME_PER_FILE):
ds[i] = img + i%500 #Each frame has a different value to prevent caching effects
res = [filename]
for i in range(1, NFILES):
new_file = pathname%i
os.link(filename,new_file)
res.append(new_file)
return res
# Create a set of files with dummy data in them:
if len(glob.glob(pathmask)) == NFILES:
input_files = glob.glob(pathmask)
input_files.sort()
else:
for f in glob.glob(pathmask):
os.remove(f)
input_files = generate_files(generate_one_frame(build_integrator(DETECTOR)))
input_files[:5]
[5]:
['/tmp/big_0000.h5',
'/tmp/big_0001.h5',
'/tmp/big_0002.h5',
'/tmp/big_0003.h5',
'/tmp/big_0004.h5']
[6]:
#This is allows to create and destroy shared numpy arrays
def create_shared_array(shape, dtype="float32", name=SHARED_NAME, create=False):
if create:
ary = SharedArray.create(name, shape, dtype=dtype)
else:
ary = SharedArray.attach(name)
return ary
def release_shared(name=SHARED_NAME):
if MAIN_PROCESS:
SharedArray.delete(name)
result_array = create_shared_array(array_shape, dtype, SHARED_NAME, create=True)
[7]:
def worker(rank, queue, shm_name, counter):
"""Function representing one worker, used in a pool of worker.
:param rank: integer, index of the worker.
:param queue: input queue, expects Item with index and name of the file to process
:param shm_name: name of the output shared memory to put integrated intensities
:param counter: decremented when quits
:return: nothing, used in a process.
"""
def new_engine(engine, wg):
"Change workgroup size of an engine"
return engine.__class__((engine._data, engine._indices, engine._indptr),
engine.size, empty=engine.empty, unit=engine.unit,
bin_centers=engine.bin_centers, azim_centers = engine.azim_centers,
ctx=engine.ctx, block_size=wg)
#imports:
import pyFAI
import numpy
import SharedArray
from silx.opencl.codec.bitshuffle_lz4 import BitshuffleLz4
import h5py
import json
import sys
#load parameters:
for k,v in json.load(open("param.json")).items():
globals()[k] = v
#Start up the integrator:
ai = pyFAI.load({"detector": DETECTOR,
"wavelength": 1e-10,
"rot3":0})
blank = numpy.zeros(ai.detector.shape, dtype="uint32")
method = ("full", "csr", "opencl", DEVICES[rank%len(DEVICES)])
res = ai.integrate1d(blank, NBINS, method=method)
omega = ai.solidAngleArray()
engine = ai.engines[res.method].engine
omega_crc = engine.on_device["solidangle"]
engine = new_engine(engine, 512)
gpu_decompressor = BitshuffleLz4(2000000, blank.size, dtype=blank.dtype, ctx=engine.ctx)
gpu_decompressor.block_size = 128
result_array = SharedArray.attach(SHARED_NAME)
with counter.get_lock():
counter.value += 1
#Worker is ready !
while True:
item = queue.get()
index = item.index
if index<0:
with counter.get_lock():
counter.value -= 1
return
with h5py.File(item.filename, "r") as h5:
ds = h5["data"]
for i in range(ds.id.get_num_chunks()):
filter_mask, chunk = ds.id.read_direct_chunk(ds.id.get_chunk_info(i).chunk_offset)
if filter_mask == 0:
# print(f"{rank}: process frame #{i}")
dec = gpu_decompressor(chunk)
intensity = engine.integrate_ng(dec, solidangle=omega, solidangle_checksum=omega_crc).intensity
result_array[index, i,:] = intensity.astype(dtype)
[8]:
def build_pool(nbprocess, queue, shm_name, counter):
"""Build a pool of processes with workers, and starts them"""
pool = []
for i in range(nbprocess):
process = Process(target=worker, name=f"worker_{i:02d}", args=(i, queue, shm_name, counter))
process.start()
pool.append(process)
while counter.value<nbprocess:
time.sleep(1)
return pool
def end_pool(pool, queue):
"""Ends all processes from a pool by sending them a "kill-pill"""
for process in pool:
queue.put(Item(-1, None))
# Build the pool of workers
queue = mpctx.Queue()
counter = mpctx.Value("i", 0)
pool = build_pool(NWORKERS, queue, SHARED_NAME, counter)
pool
[8]:
[<Process name='worker_00' pid=226160 parent=225643 started>,
<Process name='worker_01' pid=226161 parent=225643 started>,
<Process name='worker_02' pid=226162 parent=225643 started>,
<Process name='worker_03' pid=226226 parent=225643 started>]
[9]:
start_time = time.perf_counter()
for idx, fn in enumerate(input_files):
queue.put(Item(idx, fn))
end_pool(pool, queue)
counter.value
[9]:
4
[10]:
while counter.value:
time.sleep(1)
run_time = time.perf_counter()-start_time
print(f"run-time: {run_time:.1f}s")
run-time: 677.946s
[11]:
result_array
[11]:
array([[[9.79569473e+01, 9.78041000e+01, 9.82191238e+01, ...,
5.50363541e-01, 5.63470900e-01, 8.26274157e-01],
[9.89569473e+01, 9.88041077e+01, 9.92191238e+01, ...,
1.62667990e+00, 1.63994408e+00, 1.90288854e+00],
[9.99569473e+01, 9.98041077e+01, 1.00219124e+02, ...,
2.70299625e+00, 2.71641731e+00, 2.97950292e+00],
...,
[5.93956970e+02, 5.93804199e+02, 5.94219360e+02, ...,
5.34403198e+02, 5.34494141e+02, 5.34827026e+02],
[5.94956970e+02, 5.94804199e+02, 5.95219299e+02, ...,
5.35479553e+02, 5.35570618e+02, 5.35903625e+02],
[5.95956970e+02, 5.95804199e+02, 5.96219360e+02, ...,
5.36555908e+02, 5.36647095e+02, 5.36980225e+02]],
[[9.79569473e+01, 9.78041000e+01, 9.82191238e+01, ...,
5.50363541e-01, 5.63470900e-01, 8.26274157e-01],
[9.89569473e+01, 9.88041077e+01, 9.92191238e+01, ...,
1.62667990e+00, 1.63994408e+00, 1.90288854e+00],
[9.99569473e+01, 9.98041077e+01, 1.00219124e+02, ...,
2.70299625e+00, 2.71641731e+00, 2.97950292e+00],
...,
[5.93956970e+02, 5.93804199e+02, 5.94219360e+02, ...,
5.34403198e+02, 5.34494141e+02, 5.34827026e+02],
[5.94956970e+02, 5.94804199e+02, 5.95219299e+02, ...,
5.35479553e+02, 5.35570618e+02, 5.35903625e+02],
[5.95956970e+02, 5.95804199e+02, 5.96219360e+02, ...,
5.36555908e+02, 5.36647095e+02, 5.36980225e+02]],
[[9.79569473e+01, 9.78041000e+01, 9.82191238e+01, ...,
5.50363541e-01, 5.63470900e-01, 8.26274157e-01],
[9.89569473e+01, 9.88041077e+01, 9.92191238e+01, ...,
1.62667990e+00, 1.63994408e+00, 1.90288854e+00],
[9.99569473e+01, 9.98041077e+01, 1.00219124e+02, ...,
2.70299625e+00, 2.71641731e+00, 2.97950292e+00],
...,
[5.93956970e+02, 5.93804199e+02, 5.94219360e+02, ...,
5.34403198e+02, 5.34494141e+02, 5.34827026e+02],
[5.94956970e+02, 5.94804199e+02, 5.95219299e+02, ...,
5.35479553e+02, 5.35570618e+02, 5.35903625e+02],
[5.95956970e+02, 5.95804199e+02, 5.96219360e+02, ...,
5.36555908e+02, 5.36647095e+02, 5.36980225e+02]],
...,
[[5.96956970e+02, 5.96804199e+02, 5.97219299e+02, ...,
5.37632202e+02, 5.37723572e+02, 5.38056824e+02],
[9.79569473e+01, 9.78041000e+01, 9.82191238e+01, ...,
5.50363541e-01, 5.63470900e-01, 8.26274157e-01],
[9.89569473e+01, 9.88041077e+01, 9.92191238e+01, ...,
1.62667990e+00, 1.63994408e+00, 1.90288854e+00],
...,
[5.93956970e+02, 5.93804199e+02, 5.94219360e+02, ...,
5.34403198e+02, 5.34494141e+02, 5.34827026e+02],
[5.94956970e+02, 5.94804199e+02, 5.95219299e+02, ...,
5.35479553e+02, 5.35570618e+02, 5.35903625e+02],
[5.95956970e+02, 5.95804199e+02, 5.96219360e+02, ...,
5.36555908e+02, 5.36647095e+02, 5.36980225e+02]],
[[5.96956970e+02, 5.96804199e+02, 5.97219299e+02, ...,
5.37632202e+02, 5.37723572e+02, 5.38056824e+02],
[9.79569473e+01, 9.78041000e+01, 9.82191238e+01, ...,
5.50363541e-01, 5.63470900e-01, 8.26274157e-01],
[9.89569473e+01, 9.88041077e+01, 9.92191238e+01, ...,
1.62667990e+00, 1.63994408e+00, 1.90288854e+00],
...,
[5.93956970e+02, 5.93804199e+02, 5.94219360e+02, ...,
5.34403198e+02, 5.34494141e+02, 5.34827026e+02],
[5.94956970e+02, 5.94804199e+02, 5.95219299e+02, ...,
5.35479553e+02, 5.35570618e+02, 5.35903625e+02],
[5.95956970e+02, 5.95804199e+02, 5.96219360e+02, ...,
5.36555908e+02, 5.36647095e+02, 5.36980225e+02]],
[[5.96956970e+02, 5.96804199e+02, 5.97219299e+02, ...,
5.37632202e+02, 5.37723572e+02, 5.38056824e+02],
[9.79569473e+01, 9.78041000e+01, 9.82191238e+01, ...,
5.50363541e-01, 5.63470900e-01, 8.26274157e-01],
[9.89569473e+01, 9.88041077e+01, 9.92191238e+01, ...,
1.62667990e+00, 1.63994408e+00, 1.90288854e+00],
...,
[5.93956970e+02, 5.93804199e+02, 5.94219360e+02, ...,
5.34403198e+02, 5.34494141e+02, 5.34827026e+02],
[5.94956970e+02, 5.94804199e+02, 5.95219299e+02, ...,
5.35479553e+02, 5.35570618e+02, 5.35903625e+02],
[5.95956970e+02, 5.95804199e+02, 5.96219360e+02, ...,
5.36555908e+02, 5.36647095e+02, 5.36980225e+02]]], dtype=float32)
[12]:
fig, ax = subplots()
ax.imshow(result_array[:,:,5])
[12]:
<matplotlib.image.AxesImage at 0x73caf4c6f070>
[13]:
print(f"Performances: {NFILES*FRAME_PER_FILE/run_time:.3f} fps")
Performances: 1475.043 fps
[14]:
release_shared(SHARED_NAME)
Conclusion
It is possible to reach 1500 frames per second on a dual-GPU computer. In this configuration, a million of Eiger4M frames are reduced in something close to 10mn.
Energy considerations for the reduction of one million frames: * Each of the 2 GPU was consuming 140 W (over the 300W TDP of one GPU) over 700s which represents 200 kJ (55.5 Wh) for the data reduction. * The equivalent processing using only a 6-core workstation takes half a day (40682 s) and consumes 1561 kJ (433 Wh). * Processing on GPUs is thus close to 8x more efficient than processing on CPU only.
Other considerations: * Here reading from disk is fast enough, no need to put more than 2 processes per GPU. If reading is much slower, more can be beneficial. * Since the output array is in shared memory, one needs to have enough RAM for hosting it.